You’re scrolling through Instagram and spot a pair of sneakers you absolutely love, but you have zero idea what brand they are, what they’re called, or where to buy them. You type every description you can think of into Google. Nothing useful comes up.
That frustration? That’s exactly the gap AI visual search was built to close.
We’ve been locked into text-based search for decades. But language has limits. Sometimes what you see simply can’t be captured in words, and that’s where AI visual search is rewriting the rules entirely.
In this guide, we’ll break down exactly how does AI visual search works under the hood, why it’s smarter than traditional image search, which technologies power it, and where it’s headed next. Whether you’re a curious tech reader, a developer, or a business owner trying to understand what’s coming, this is your complete resource.
What Is AI Visual Search? (And Why It’s Different From Image Search)
Before we dive deep, let’s clear up a common misconception.
Traditional Image Search
Traditional image search (like early Google Images) worked by matching keywords attached to image file names, alt text, and surrounding content. It wasn’t actually reading the image; it was reading the text around it.
AI Visual Search
AI visual search is fundamentally different. It analyzes the image’s content objects, colors, shapes, textures, spatial relationships, and context to understand what’s in it and return meaningful results.
Think of it like the difference between a librarian who reads book titles on the spine versus one who has actually read every book and can tell you exactly which chapter contains the answer you’re looking for.
Key Takeaway
AI visual search doesn’t rely on keywords or metadata. It uses machine learning to see and interpret images the same way a human brain would, only much, much faster.
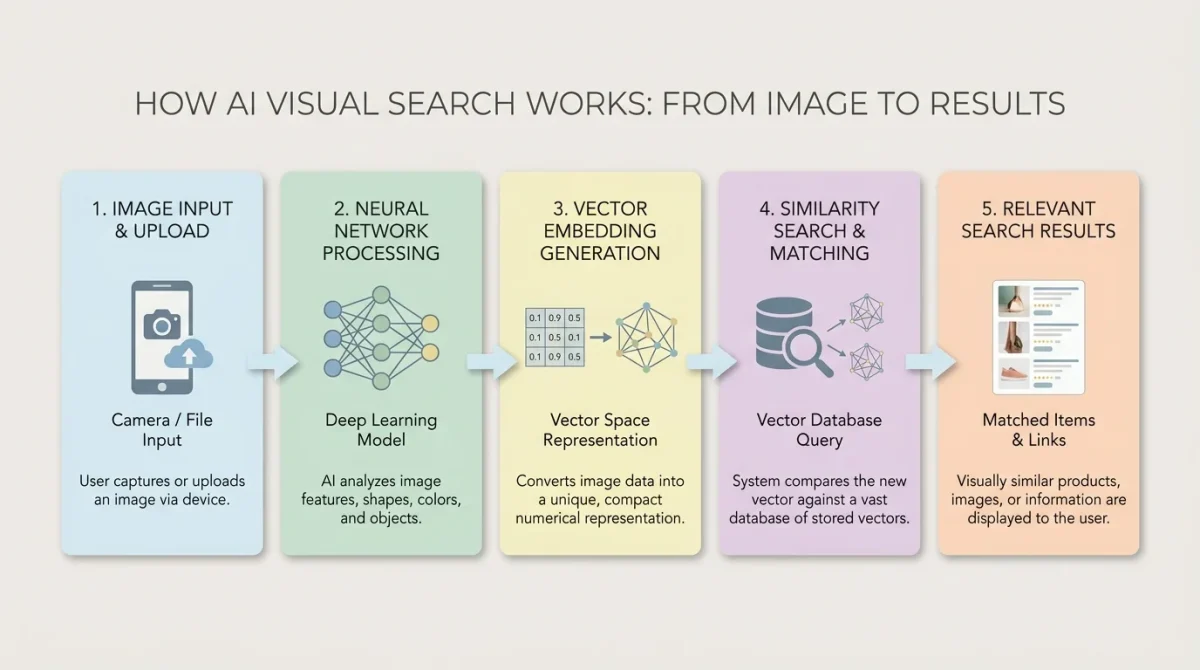
How Does AI Visual Search Work? The Core Technology Explained
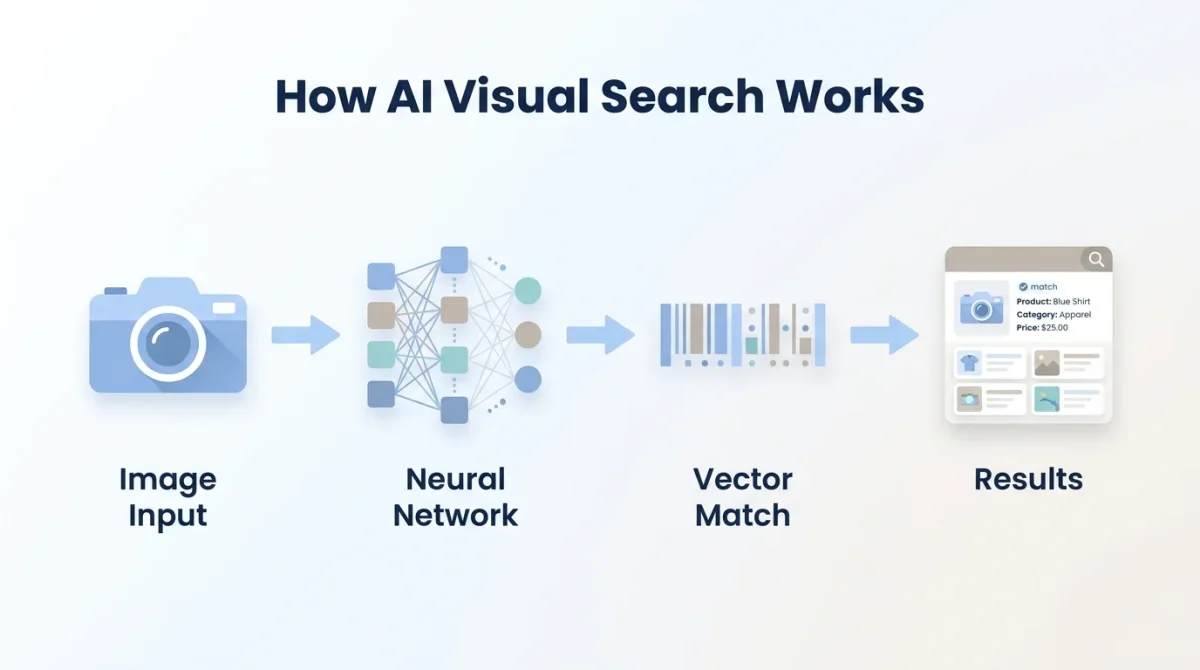
To truly understand AI visual search, you need to understand the stack of technologies working together beneath the surface. It’s not one single algorithm; it’s a layered system of interconnected AI models.
1. Computer Vision: Teaching Machines to See
At the foundation of every AI visual search system is computer vision (CV), the branch of AI that enables machines to interpret and understand visual information from the world.
When you upload a photo to a visual search engine, computer vision algorithms immediately begin scanning the image pixel by pixel. But they don’t just see pixels, they’re trained to recognize patterns, edges, gradients, and shapes that correspond to real-world objects.
Modern CV systems can simultaneously detect multiple objects within a single image. A photo of a kitchen might be parsed as: countertop, microwave, coffee maker, window, plant, and marble tile, all identified, categorized, and tagged within milliseconds.
2. Convolutional Neural Networks (CNNs): The Backbone of Image Recognition
The real workhorse of AI visual search is the Convolutional Neural Network (CNN), a deep learning architecture specifically designed to process grid-structured data, such as images. Here’s how a CNN processes an image in simplified terms:
Step 1 — Feature Extraction: The network applies filters (called kernels) across the image to detect basic features like edges, curves, and color gradients in the early layers.
Step 2 — Hierarchical Pattern Recognition: As data moves through deeper layers, the network begins to recognize increasingly complex patterns. A circle becomes an eye, edges become a face, colors and shapes combine into a shoe.
Step 3 — Classification: The final layers output a probability distribution, essentially the model’s confidence score that the image contains specific objects or belongs to specific categories.
This is why CNNs can reliably distinguish a Labrador from a Golden Retriever, or a running shoe from a dress shoe; they’ve been trained on millions of labeled images to recognize subtle distinguishing features.
Pro Tip
The accuracy of a CNN-based visual search system is directly tied to the quality and diversity of its training data. Systems trained on narrow datasets produce narrow results. The best AI visual search engines are trained on billions of images across thousands of categories.
3. Embedding Vectors: Translating Images Into Math
Once a CNN has analyzed an image, the system converts the visual information into a high-dimensional embedding vector, essentially a numerical fingerprint unique to that image’s visual content.
Think of it this way: every image gets converted into a list of hundreds or thousands of numbers. Similar-looking images produce similar vectors. A red sneaker and a blue sneaker will have vectors that are close to each other in mathematical space, while a sneaker and a chair will have vectors very far apart.
This mathematical representation enables similarity search. The system compares the query image’s vector against a database of pre-computed vectors to find the closest matches.
The underlying math often involves techniques such as cosine similarity or Euclidean distance to measure the distance between two vectors.
4. Transformer Models and Vision Transformers (ViTs): The Next Evolution
While CNNs dominated image recognition for years, the field has been shifting toward Vision Transformers (ViTs), a class of model architecture originally designed for natural language processing (NLP) and later adapted for image understanding.
CLIP (Contrastive Language-Image Pre-Training) by OpenAI is a landmark example. CLIP was trained on hundreds of millions of image-text pairs scraped from the internet. It learned to map images and text to the same mathematical space, enabling it to match a text query such as ‘red high heels on a white background’ directly to relevant images, without any fine-tuning.
This is a massive leap. Instead of relying on keyword tags, CLIP and similar models truly understand the relationship between what’s in an image and what people say about it.
Google’s Vision Transformer (ViT) took this further by applying the same self-attention mechanism from NLP transformers to image patches, dividing images into a grid and analyzing the relationships between all patches simultaneously, rather than processing them sequentially as a CNN does.
The End-to-End Pipeline: What Happens When You Search With an Image
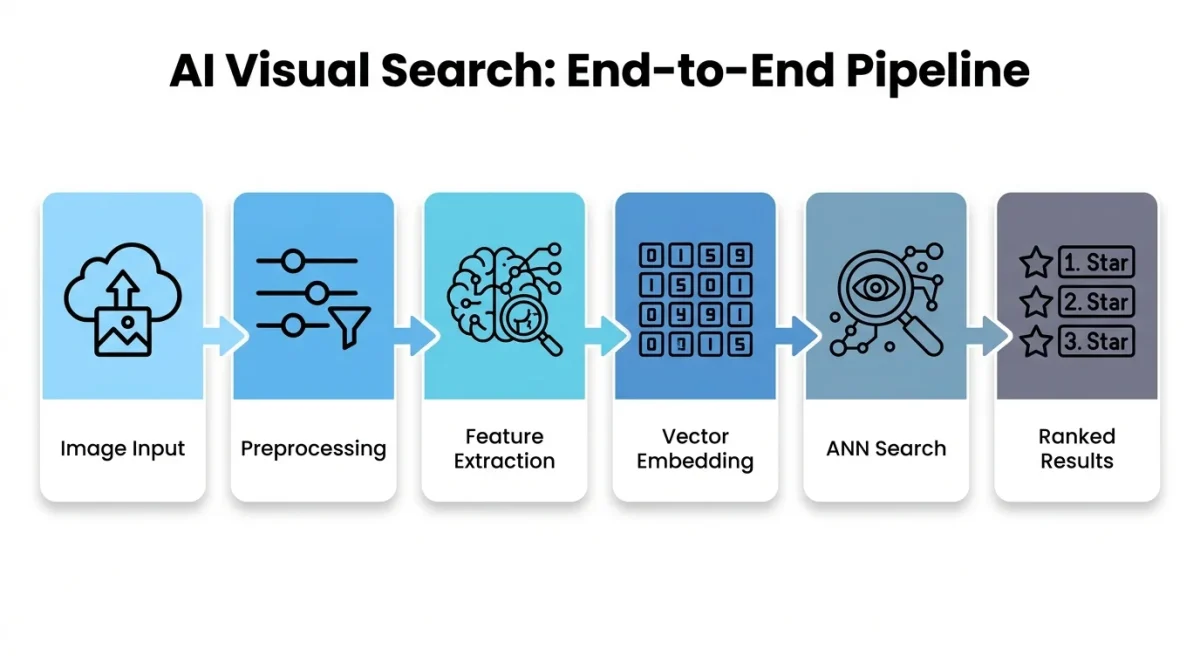
Let’s walk through the complete lifecycle of a visual search query from the moment you snap a photo to when results appear on your screen.
Step 1: Image Ingestion and Preprocessing
When you upload an image (or point your camera at something), the system first preprocesses it. This includes:
- Resizing the image to a standard input dimension, the model expects.
- Normalizing pixel values to a standard range.
- Noise reduction to improve accuracy on low-quality or blurry images.
- Object segmentation to isolate the primary subject from the background (especially important in product search)
Step 2: Feature Extraction
The preprocessed image is passed through the neural network. Intermediate layer outputs, rather than the final classification output, are used to extract rich feature representations. These features capture texture, shape, color distribution, object relationships, and more.
Step 3: Vector Embedding
The features are compressed into a compact embedding vector and stored or compared against an existing index.
Step 4: Approximate Nearest Neighbor (ANN) Search
Comparing a query vector against a database of millions or billions of vectors in real time requires specialized Approximate Nearest Neighbor (ANN) algorithms. Tools like FAISS (Facebook AI Similarity Search) and ScaNN (Scalable Nearest Neighbors) by Google enable sub-second retrieval across billion-scale datasets by intelligently narrowing the search space using techniques like hierarchical clustering and product quantization.
Step 5: Ranking and Reranking
Raw similarity isn’t always enough. The results are then passed through a ranking model that considers additional signals:
- Relevance to the user’s intent.
- Engagement data (what did users click on after similar queries?)
- Contextual signals (location, device, prior search history)
- Commercial signals (in e-commerce visual search, product availability and pricing)
Step 6: Results Delivery
Finally, the ranked results are returned to the user, usually as a gallery of visually similar items, augmented with metadata such as product names, prices, links, or related searches.
Real-World Applications of AI Visual Search
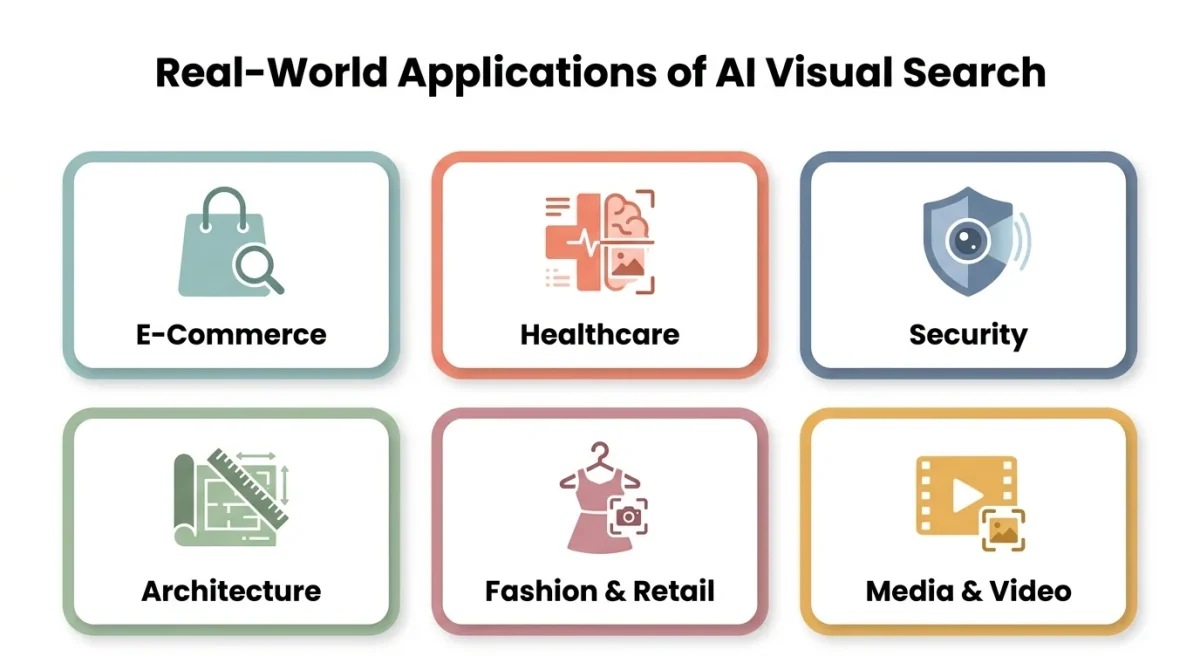
Understanding the technology is only half the picture. What makes AI visual search genuinely exciting is where it’s being applied.
E-Commerce: Find It, Buy It
Pinterest Lens, Google Lens, and Amazon’s StyleSnap are prime examples of visual search transforming retail. A shopper who spots a piece of furniture in a magazine can photograph it and instantly find identical or similar products available for purchase online.
Retailers using visual search report measurable lifts in conversion rates because it eliminates the friction of translating what you see into words that a text-based search engine can understand.
Healthcare: Diagnostic Imaging
AI visual search is being used to compare new medical scans (X-rays, MRIs, CT scans) against vast databases of annotated historical cases. Radiologists can query by image to surface similar cases, helping identify patterns associated with specific conditions faster and with greater accuracy.
Security and Surveillance
Law enforcement and security agencies use visual search to match faces, license plates, or objects across large video archives. Forensic investigators can query by image to find appearances of a specific item across hours of footage.
Architecture and Design
Designers and architects use visual search to find reference images, source materials, or precedents based on aesthetic similarity rather than keyword guessing. Tools like Midjourney and other AI image generators are increasingly incorporating visual search to enable style matching with reference images.
Fashion and Retail: The Shop the Look Revolution
Shop the Look, now standard on platforms like Pinterest, Instagram, and ASOS, uses AI visual search to identify every garment and accessory in a photo and link them directly to shoppable products.
Key Players and Platforms in AI Visual Search
| Platform | Visual Search Tool | Core Technology |
| Google Lens | Multitask Unified Model (MUM) + Vision Transformer (ViT) & CNNs | |
| Pinterest Lens | Convolutional Neural Networks (CNNs) + Visual Embedding Search | |
| Amazon | StyleSnap | Deep Learning + Multiple CNNs for Product Catalog Matching |
| Bing | Visual Search | Microsoft Florence Model + Large-scale Multi-modal Pre-training |
| Alibaba | Pailitao | Qwen LLM + Large-scale ANN (Approximate Nearest Neighbor) Search |
| Apple | Visual Look Up | On-device Neural Engine + Apple Intelligence (Visual Intelligence) |
Each of these platforms has invested hundreds of millions of dollars into its visual search infrastructure, a clear signal that this technology is becoming core to how the web works.
AI Visual Search vs. Traditional Image Search
| Feature | Traditional Image Search | AI Visual Search |
| Query Type | Text keywords | Image, photo, or screenshot |
| Basis of Results | Metadata, alt text, surrounding text | Visual content analysis |
| Object Recognition | Relies on human labeling | Automated via deep learning |
| Semantic Understanding | Limited | High (especially with CLIP/ViT models) |
| Cross-modal Matching | No | Yes (image ↔ text interchangeable) |
| Real-time Accuracy | High for known items | High and improving constantly |
| Use Case Breadth | General web search | Retail, healthcare, security, design, and more |
Challenges and Limitations of AI Visual Search
No technology is without its rough edges, and AI visual search is no exception.
Bias in Training Data
If a model is trained predominantly on images from Western contexts, it may underperform for objects, fashion styles, or faces more common in other regions. This is an ongoing area of concern and active research.
Privacy and Ethical Issues
Facial recognition, a close cousin of visual search, has raised serious civil liberties concerns. When visual search is applied to identifying individuals in public spaces without consent, the ethical implications become significant. Many jurisdictions are actively drafting regulations in this space.
The Long Tail Problem
AI visual search performs excellently on common, well-represented object categories. But for niche, rare, or highly specialized items such as antique medical instruments, obscure auto parts, or regional clothing styles, accuracy drops considerably.
Adversarial Inputs
Visual search systems can be fooled by adversarial images that appear identical to humans yet contain subtle pixel-level perturbations that cause the model to misclassify them. This is an active area of AI security research.
Computational Cost
Running a full-scale visual search pipeline in real time requires substantial compute resources. Edge deployment of these models on smartphones requires aggressive model compression techniques, such as quantization and pruning.
The Future of AI Visual Search: What’s Coming Next
AI visual search is evolving at a pace that’s genuinely hard to keep up with. Here’s where the field is heading:
Multimodal Search: Text + Image + Voice Combined
The next frontier is multimodal search, where a user can combine text, image, voice, and even video in a single query. Google’s MUM (Multitask Unified Model) and Gemini are early examples: they can process a photo of a mountain and a question like Is this trail difficult for beginners? simultaneously, returning a unified, contextually aware answer.
Augmented Reality Integration
As AR glasses mature (Apple Vision Pro, Meta Orion, and others in the pipeline), visual search will become ambient and always-on. Glance at something, and your device surfaces information, prices, reviews, and purchase options overlaid in your field of view.
Video Visual Search
Static image search is just the beginning. Video visual search identifying objects, brands, and scenes across video content in real time is already being prototyped. This has enormous implications for content monetization, product placement analytics, and media monitoring.
On-Device AI Visual Search
Apple’s Visual Look Up is an early example of on-device visual search; no data leaves your phone. As mobile neural processing units (NPUs) become more powerful, this pattern will become the standard, addressing privacy concerns while improving performance.
Personalized Visual Search
Future systems will learn your personal visual preferences over time, your aesthetic sensibilities, brand affinities, and color preferences and tailor results accordingly. Visual search becomes less about finding the match and more about finding your match.
Key Takeaways
- AI visual search works by combining computer vision, deep neural networks, embedding vectors, and nearest-neighbor search to interpret and match images based on visual content rather than keywords.
- CNNs and Vision Transformers (ViTs) are the two dominant architectures powering modern visual search systems.
- Models like CLIP have enabled true cross-modal search, matching text queries to images and vice versa, with high accuracy.
- Major platforms, including Google Lens, Pinterest Lens, and Amazon StyleSnap, have already made visual search mainstream for consumers.
- Key challenges include training data bias, privacy concerns, and the computational cost of real-time inference.
- The future of visual search is multimodal, ambient, and personalized, converging with AR, video, and on-device AI.
Final Thoughts
AI visual search isn’t a gimmick or a feature on the margins of the web. It’s a foundational shift in how humans interact with information, one that makes the internet more intuitive, more accessible, and more closely aligned with how we actually perceive the world.
We don’t think in keywords. We think in images, scenes, and objects. AI visual search is finally building a search experience that thinks like it.
For businesses, creators, and developers, the time to understand and optimize for visual search isn’t eventually. It’s now.
Frequently Asked Questions (FAQs)
How accurate is AI visual search today?
Top-tier systems like Google Lens achieve remarkably high accuracy on common objects, landmarks, plants, and products. Accuracy for niche or rare items is still improving, but trails that for well-represented categories.
Is AI visual search the same as reverse image search?
Not quite. A reverse image search (like Google's original Search by image feature) looks for visually identical or near-identical images online. AI visual search goes further: it understands an image's content and can find visually similar items, even if they're not exact matches.
Can AI visual search identify people's faces?
Some systems can perform facial recognition, but most consumer-facing visual search tools (including Google Lens and Pinterest) deliberately avoid returning results that identify private individuals, citing privacy concerns. Deployment of facial identification is mostly restricted to law enforcement and security contexts and is subject to increasing regulatory scrutiny.
What is the best AI visual search tool available today?
Google Lens is widely considered the most capable general-purpose AI visual search tool due to its integration with Google's Knowledge Graph, Maps, Shopping, and Translate services. For e-commerce, Pinterest Lens and Amazon StyleSnap are highly specialized and effective.
How can businesses optimize for AI visual search?
Use high-resolution, contextually relevant original images. Implement structured data markup (especially Product and ImageObject schema). Ensure images are mobile-optimized and fast-loading. Use descriptive, semantically rich alt text and captions. And ensure your product images are indexed and crawlable by search engines.
Will AI visual search replace text search?
It won't replace text search; it will complement it. Multimodal systems that combine text, image, voice, and video queries are the likely future. Text remains essential for abstract concepts, research, and navigational queries; visual search excels for product discovery, spatial understanding, and real-world object identification.












{kind=link}
{kind=link}